Para preparar uma base de dados de imagens para treinar uma rede neural no reconhecimento de objectos, é necessário reconhecer as imagens da base de dados. Isto significa atribuir-lhes uma etiqueta e uma zona de reconhecimento.
Este tutorial dá seguimento ao artigo sobre a criação de um banco de imagens.
Objetivo da preparação
O objetivo é criar conjuntos de dados que facilitem o treino com as ferramentas TensorFlow, Yolo ou Keras.
Há duas formas de o fazer:
- Utilizar labelImg
- Criar uma arquitetura de pastas e utilizar um script (formação apenas com Keras)
Preparar um banco de imagens com labelImg
Pode descarregar e instalar o labelImg
- Linux
python3 -m pip install labelImg labelImg
- Janelas
Siga as instruções de compilação no github. Também pode encontrar um executável labelImg.exe
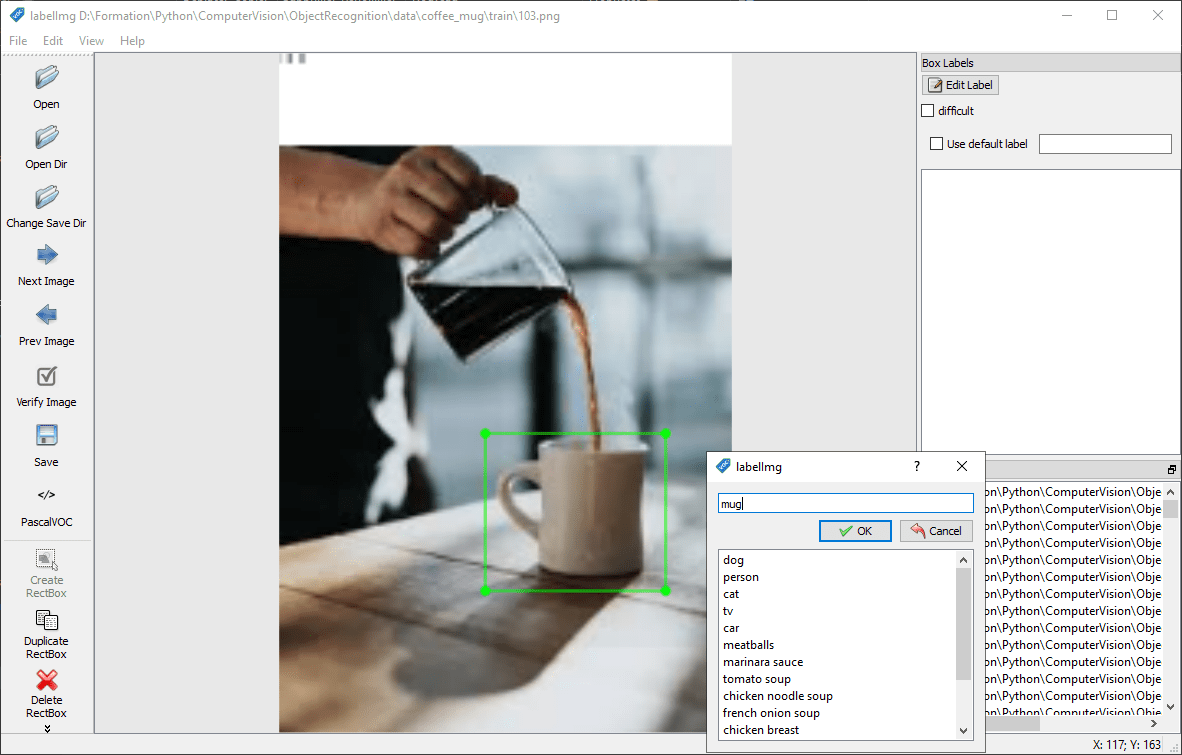
Adicionar uma caixa e uma etiqueta
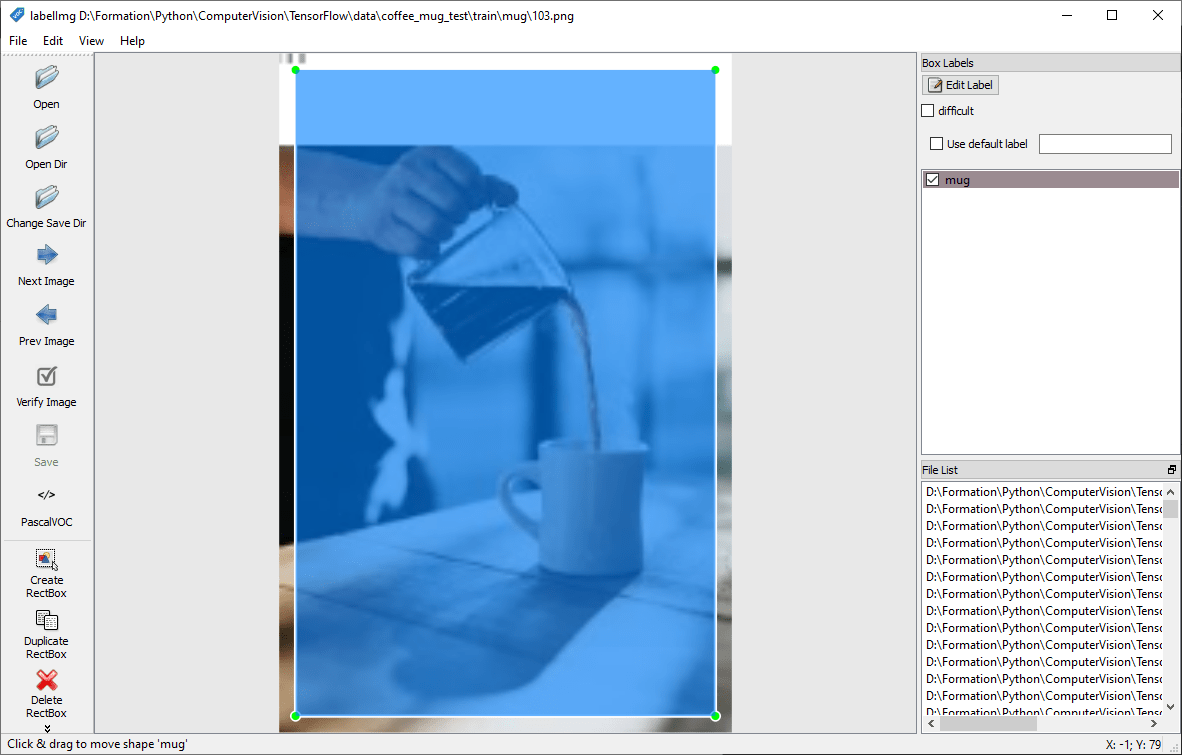
Inicie o labelImg e seleccione a pasta utilizando o botão “Open Dir”.
Para cada imagem, rodeará o objeto a detetar e atribuir-lhe-á um nome (etiqueta) utilizando o botão “Criar RectBox”.
Nota: evite ultrapassar a imagem ao desenhar a caixa. Isso pode causar problemas durante o treino.
Converter para o formato PascalVOC
Converter para o formato YOLO
Nota: Pode guardar os dois formatos em simultâneo ou guardar em VOC e converter para YOLO utilizando o script convert_voc_to_yolo.py.
Preparar um banco de imagens com uma arquitetura de pastas
A ideia é colocar as imagens em subpastas com o nome da classe. Para o treino, o banco de imagens deve conter entre 1 e 3 pastas: treino, teste, validação (as pastas de teste e validação são opcionais porque podem ser criadas a partir da primeira pasta).
N.B.: este método requer um único objeto por imagem
- images
- train
- gatos
- cães
- validation
- gatos
- cães
- train
Para criar os ficheiros que contêm o nome e as informações da zona de deteção a partir das pastas de imagens, pode utilizar o script gerar_arquivos_voc.py:
- os caminhos de acesso às várias pastas (pastas[‘train’
Os nomes das classes serão definidos pelos nomes das pastas e a zona de deteção pelo tamanho da imagem.
gerar_arquivos_voc.py
import glob
import os
import pickle
import cv2
import xml.etree.ElementTree as ET
import xml.dom.minidom
from os import listdir, getcwd
from os.path import join
dirs = ['train', 'test']
classes = ['mug']
def getImagesInDir(dir_path):
image_list = []
for filename in glob.glob(dir_path + '/**/*.png', recursive=True):
image_list.append(filename)
return image_list
def generate_voc(image_path):
#get image data
dirname=os.path.dirname(image_path)
foldername=dirname.split('\\')[-1]
basename = os.path.basename(image_path)
basename_no_ext = os.path.splitext(basename)[0]
im = cv2.imread(image_path)
h,w,c=im.shape
root = ET.Element('annotation')
folder = ET.SubElement(root, 'folder')
folder.text=foldername
filename = ET.SubElement(root, 'filename')
filename.text=basename
path = ET.SubElement(root, 'path')
path.text=image_path
source = ET.SubElement(root, 'source')
database = ET.SubElement(source, 'database')
database.text = 'Unknown'
size = ET.SubElement(root, 'size')
width = ET.SubElement(size, 'width')
width.text='{}'.format(w)
height = ET.SubElement(size, 'height')
height.text='{}'.format(h)
depth = ET.SubElement(size, 'depth')
depth.text='{}'.format(c)
segmented = ET.SubElement(root, 'segmented')
segmented.text = '0'
objec = ET.SubElement(root, 'object')
name = ET.SubElement(objec, 'name')
name.text=foldername
pose = ET.SubElement(objec, 'pose')
pose.text='Unspecified'
truncated = ET.SubElement(objec, 'truncated')
truncated.text='0'
difficult = ET.SubElement(objec, 'difficult')
difficult.text='0'
bndbox = ET.SubElement(objec, 'bndbox')
xmin = ET.SubElement(bndbox, 'xmin')
xmin.text='{}'.format(0+5)
ymin = ET.SubElement(bndbox, 'ymin')
ymin.text='{}'.format(0+5)
xmax = ET.SubElement(bndbox, 'xmax')
xmax.text='{}'.format(w-5)
ymax = ET.SubElement(bndbox, 'ymax')
ymax.text='{}'.format(h-5)
tree = ET.ElementTree(root)
outxml=join(dirname,basename_no_ext+'.xml')
tree.write(outxml)
return outxml
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(in_file):
dirname=os.path.dirname(in_file)
basename = os.path.basename(in_file)
basename_no_ext = os.path.splitext(basename)[0]
out_file = open(join(dirname, basename_no_ext + '.txt'), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
cwd = getcwd()
for dir_path in dirs:
full_dir_path = join(cwd,dir_path)
image_paths = getImagesInDir(full_dir_path)
for image_path in image_paths:
xml_path=generate_voc(image_path) #generate voc file
convert_annotation(xml_path) #convert to yolo file
print("Finished processing: " + dir_path)
Este método produz rapidamente uma base de dados que pode ser utilizada para a formação (TensorFlow e Yolo), mesmo que a zona de reconhecimento seja aproximada.
N.B.: Uma vez criados os ficheiros XML e TXT, pode abrir o lableImg para aperfeiçoar as etiquetas e a zona de deteção.