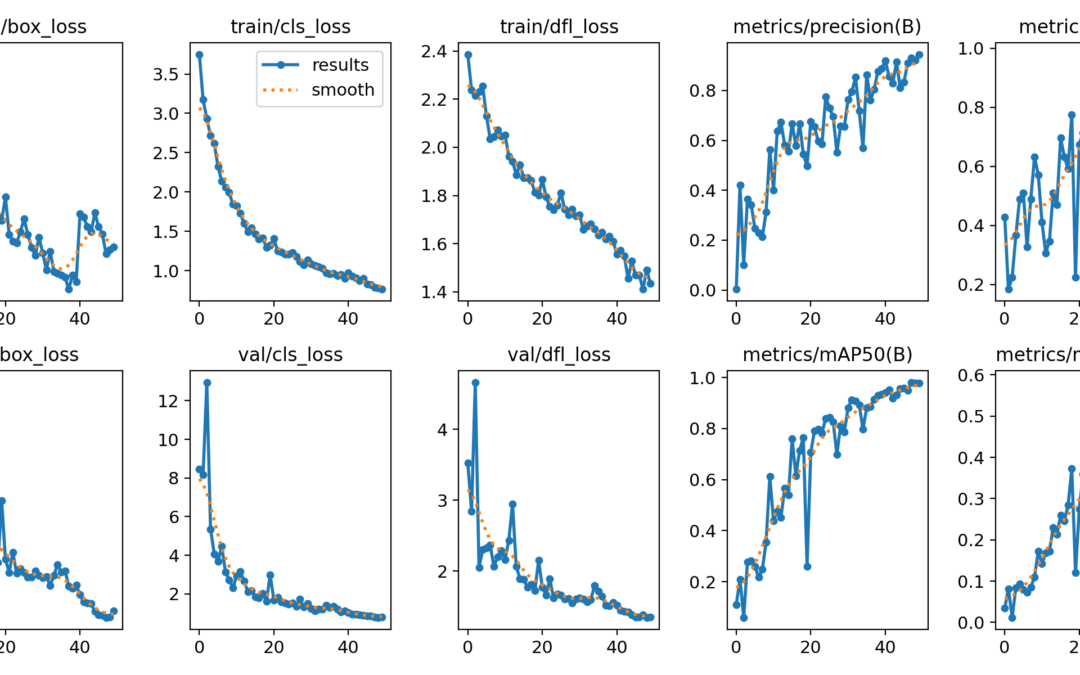
Treinar um modelo Yolo
Neste tutorial, vamos ver como treinar um modelo YOLO para reconhecimento de objectos em dados específicos. A dificuldade reside na criação do banco de imagens que será utilizado para o treino. Hardware Um computador com uma instalação Python3 Uma câmara Princípio...
Deteção de objectos no Raspberry Pi e TensorFlow Lite
Para melhorar o desempenho no Raspberry Pi, é possível utilizar a linguagem C++ e bibliotecas optimizadas para acelerar o cálculo dos modelos de deteção de objectos. É isto que o TensorFlow Lite oferece. Um bom ponto de partida é o sítio Web QEngineering. Hardware...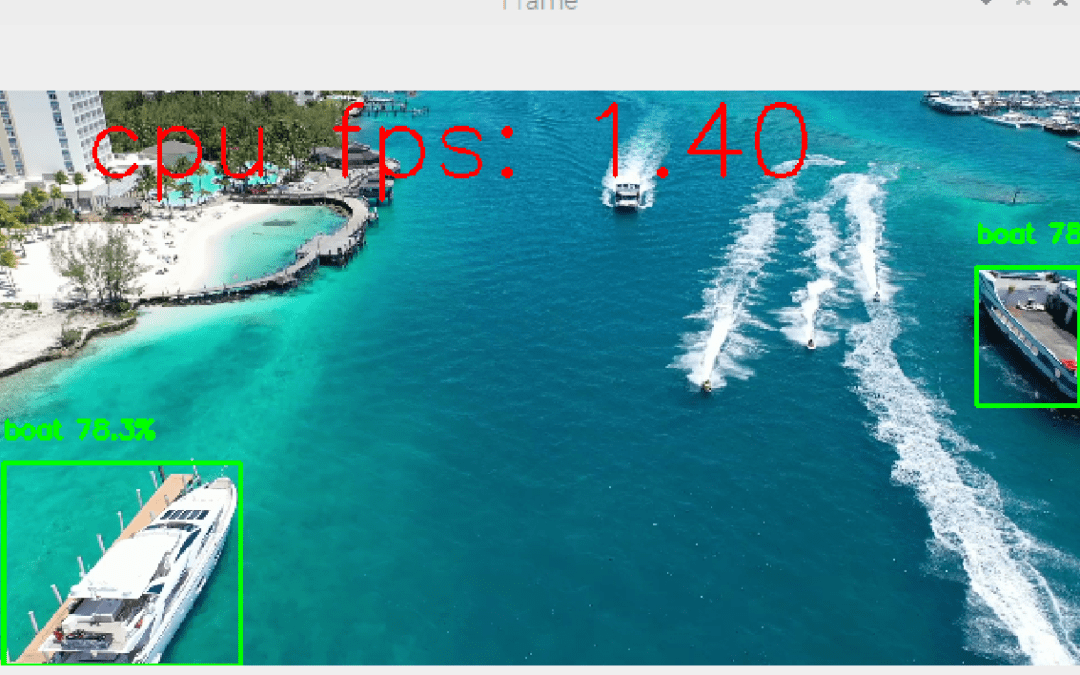
Deteção de objectos com Yolo em Raspberry Pi
É possível incorporar modelos de reconhecimento de objectos como o Yolo num Raspberry Pi. Naturalmente, devido ao seu baixo desempenho em comparação com os computadores, o desempenho é inferior em termos de reconhecimento em tempo real. No entanto, é perfeitamente...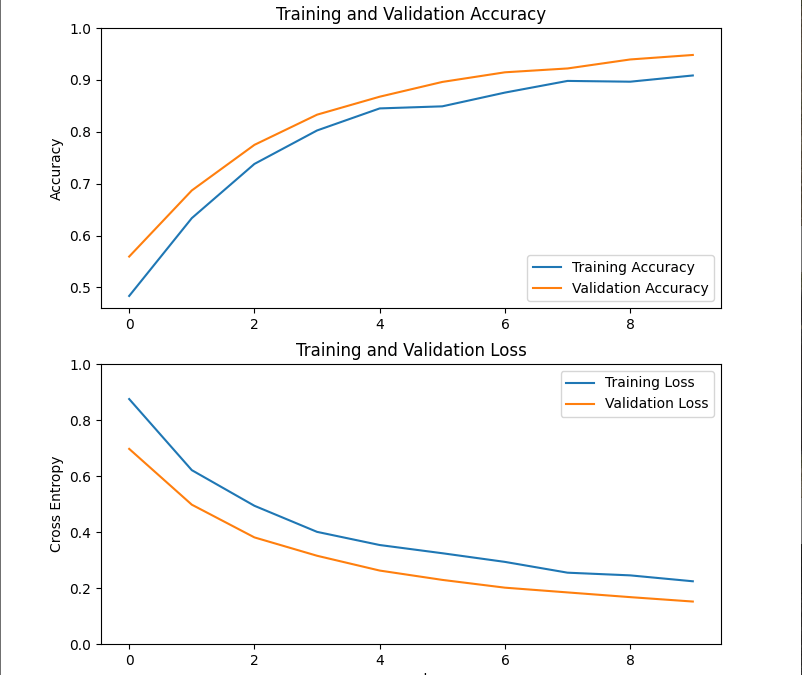
Treinar um modelo TensorFlow2 com o Keras
Neste tutorial, vamos treinar um modelo TensorFlow MobileNetV2 com o Keras para que ele possa ser aplicado ao nosso problema. Poderemos então utilizá-lo em tempo real para classificar novas imagens. Para este tutorial, partimos do princípio de que seguiu os tutoriais...License
![]()
Files are licensed under the Creative Commons – Attribution – Non-Commercial license