Para preparar una base de datos de imágenes para entrenar una red neuronal de reconocimiento de objetos, es necesario que reconozca usted mismo las imágenes de la base de datos. Esto significa darles una etiqueta y una zona de reconocimiento.
Este tutorial es la continuación del artículo sobre la creación de un banco de imágenes.
Finalidad de la preparación
El objetivo es crear conjuntos de datos que faciliten el entrenamiento con herramientas TensorFlow, Yolo o Keras.
Hay dos maneras de hacerlo:
- Utilizar labelImg
- Crear una arquitectura de carpetas y utilizar un script (sólo entrenamiento con Keras)
Preparar un banco de imágenes con labelImg
Puede descargar e instalar labelImg
- Linux
python3 -m pip install labelImg labelImg
- Windows
Siga las instrucciones de compilación en github. También puedes encontrar un ejecutable labelImg.exe
Añadir una caja y una etiqueta
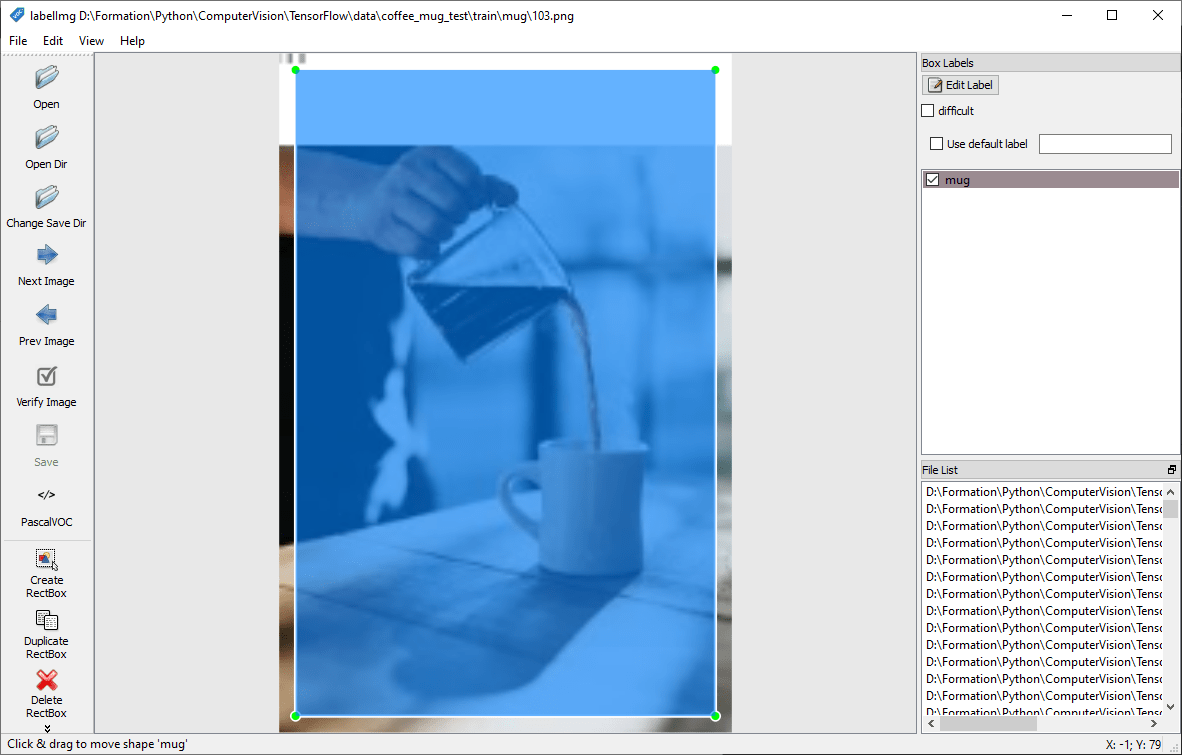
Inicie labelImg y seleccione la carpeta con el botón «Open Dir».
Para cada imagen, rodeará el objeto a detectar y le asignará un nombre (etiqueta) mediante el botón «Crear RectBox».
Nota: evite sobrepasar la imagen al dibujar el recuadro. Esto puede causar problemas durante el entrenamiento.
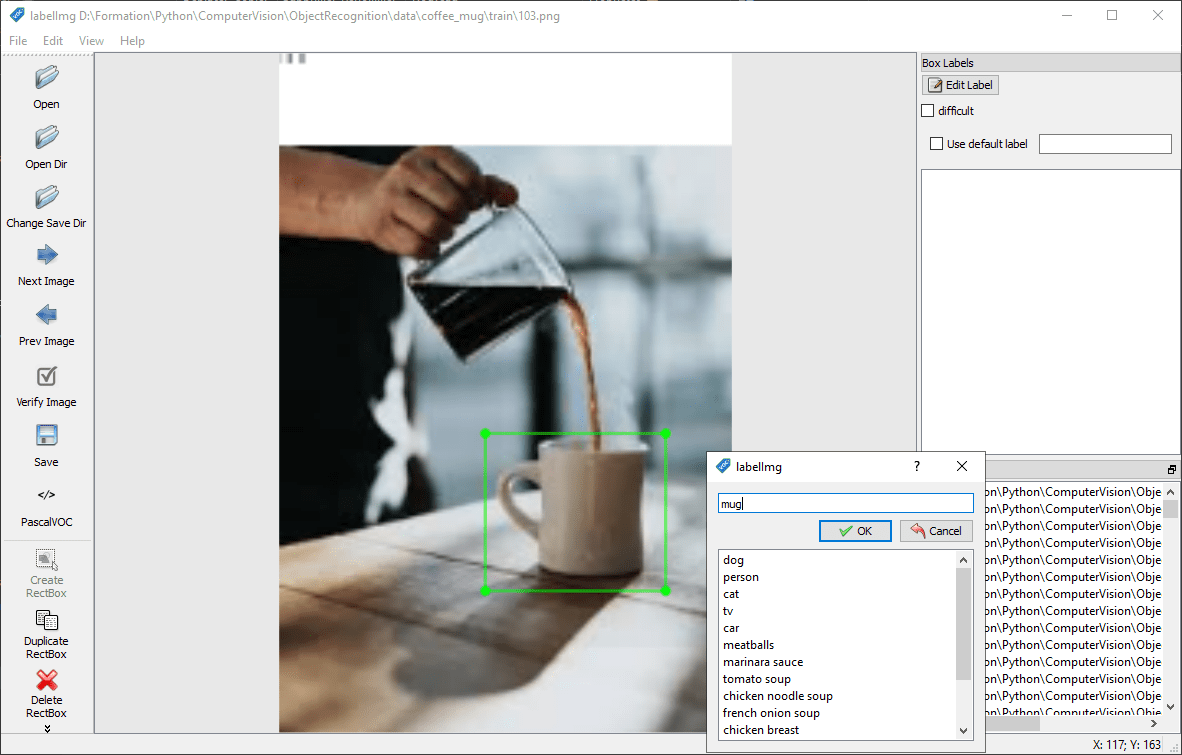
Convertir a formato PascalVOC
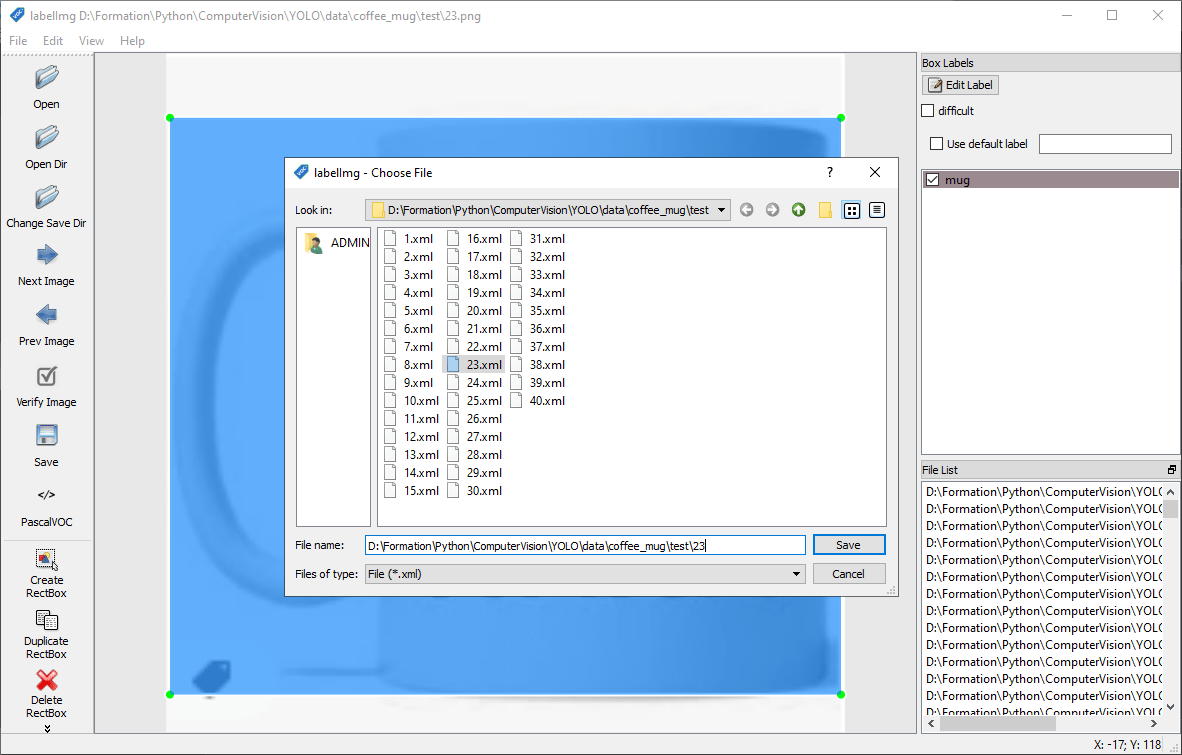
Convertir a formato YOLO
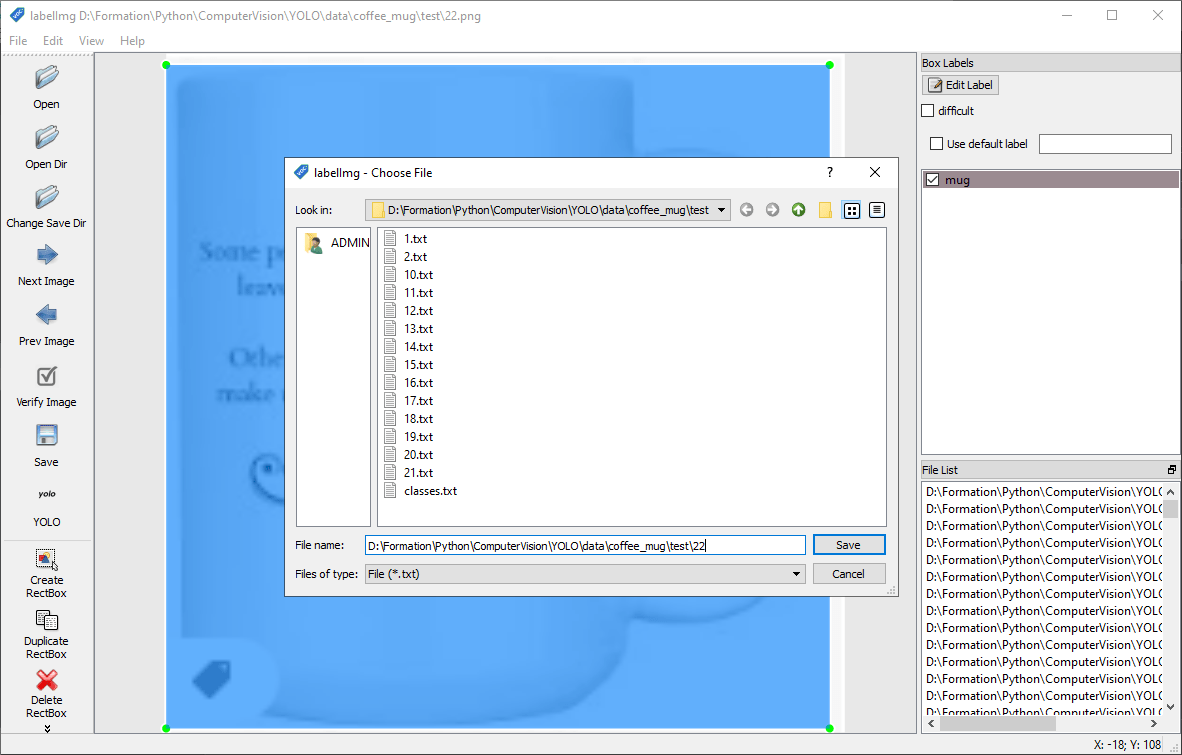
N.B.: Puede guardar ambos formatos sucesivamente o guardar en VOC y convertir a YOLO utilizando el script convert_voc_to_yolo.py.
Preparar un banco de imágenes con una arquitectura de carpetas
La idea es colocar las imágenes en subcarpetas con el nombre de la clase. Para la formación, el banco de imágenes debe contener entre 1 y 3 carpetas: formación, prueba, validación (las carpetas de prueba y validación son opcionales porque pueden crearse a partir de la primera carpeta).
N.B.: este método requiere un único objeto por imagen
- images
- train
- gatos
- perros
- validation
- gatos
- perros
- train
Para crear los archivos que contienen el nombre y la información de la zona de detección a partir de las carpetas de imágenes, puede utilizar el script generar_archivos_voc.py:
- las rutas de acceso a las distintas carpetas (carpetas[‘tren’
Los nombres de las clases se definirán por los nombres de las carpetas y la zona de detección por el tamaño de la imagen.
generar_archivos_voc.py
import glob
import os
import pickle
import cv2
import xml.etree.ElementTree as ET
import xml.dom.minidom
from os import listdir, getcwd
from os.path import join
dirs = ['train', 'test']
classes = ['mug']
def getImagesInDir(dir_path):
image_list = []
for filename in glob.glob(dir_path + '/**/*.png', recursive=True):
image_list.append(filename)
return image_list
def generate_voc(image_path):
#get image data
dirname=os.path.dirname(image_path)
foldername=dirname.split('\\')[-1]
basename = os.path.basename(image_path)
basename_no_ext = os.path.splitext(basename)[0]
im = cv2.imread(image_path)
h,w,c=im.shape
root = ET.Element('annotation')
folder = ET.SubElement(root, 'folder')
folder.text=foldername
filename = ET.SubElement(root, 'filename')
filename.text=basename
path = ET.SubElement(root, 'path')
path.text=image_path
source = ET.SubElement(root, 'source')
database = ET.SubElement(source, 'database')
database.text = 'Unknown'
size = ET.SubElement(root, 'size')
width = ET.SubElement(size, 'width')
width.text='{}'.format(w)
height = ET.SubElement(size, 'height')
height.text='{}'.format(h)
depth = ET.SubElement(size, 'depth')
depth.text='{}'.format(c)
segmented = ET.SubElement(root, 'segmented')
segmented.text = '0'
objec = ET.SubElement(root, 'object')
name = ET.SubElement(objec, 'name')
name.text=foldername
pose = ET.SubElement(objec, 'pose')
pose.text='Unspecified'
truncated = ET.SubElement(objec, 'truncated')
truncated.text='0'
difficult = ET.SubElement(objec, 'difficult')
difficult.text='0'
bndbox = ET.SubElement(objec, 'bndbox')
xmin = ET.SubElement(bndbox, 'xmin')
xmin.text='{}'.format(0+5)
ymin = ET.SubElement(bndbox, 'ymin')
ymin.text='{}'.format(0+5)
xmax = ET.SubElement(bndbox, 'xmax')
xmax.text='{}'.format(w-5)
ymax = ET.SubElement(bndbox, 'ymax')
ymax.text='{}'.format(h-5)
tree = ET.ElementTree(root)
outxml=join(dirname,basename_no_ext+'.xml')
tree.write(outxml)
return outxml
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(in_file):
dirname=os.path.dirname(in_file)
basename = os.path.basename(in_file)
basename_no_ext = os.path.splitext(basename)[0]
out_file = open(join(dirname, basename_no_ext + '.txt'), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
cwd = getcwd()
for dir_path in dirs:
full_dir_path = join(cwd,dir_path)
image_paths = getImagesInDir(full_dir_path)
for image_path in image_paths:
xml_path=generate_voc(image_path) #generate voc file
convert_annotation(xml_path) #convert to yolo file
print("Finished processing: " + dir_path)
Este método produce rápidamente una base de datos que puede utilizarse para el entrenamiento (TensorFlow y Yolo), incluso si la zona de reconocimiento es aproximada.
Nota: Una vez creados los ficheros XML y TXT, puede abrir lableImg para afinar las etiquetas y el campo de detección.