
Programación en Python con VSCode
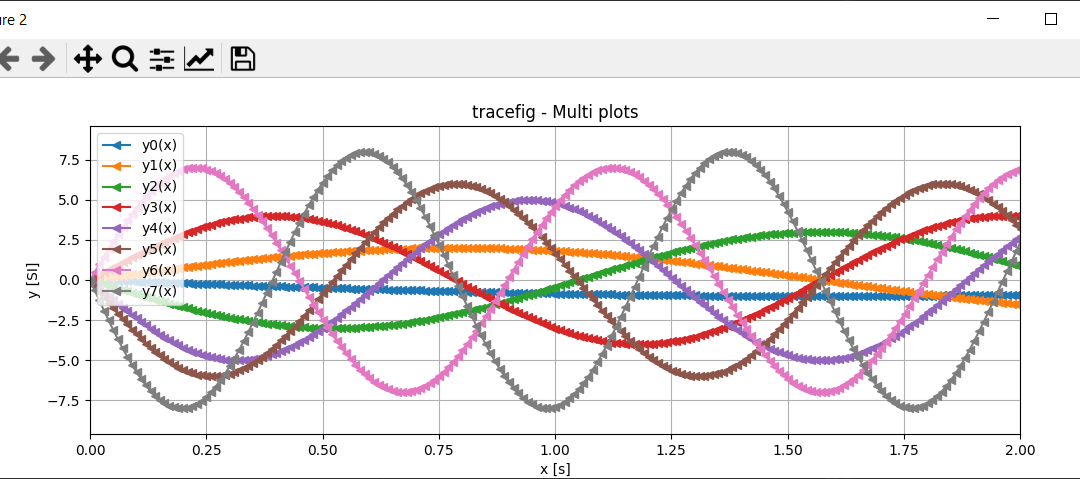
El editor de código VSCode permite crear y desarrollar proyectos en diversos lenguajes de programación, como Python y C++, gracias a una serie de extensiones. Instalación de VSCode Si aún no lo ha hecho, descargue e instale VSCode Utilizar un editor de código como...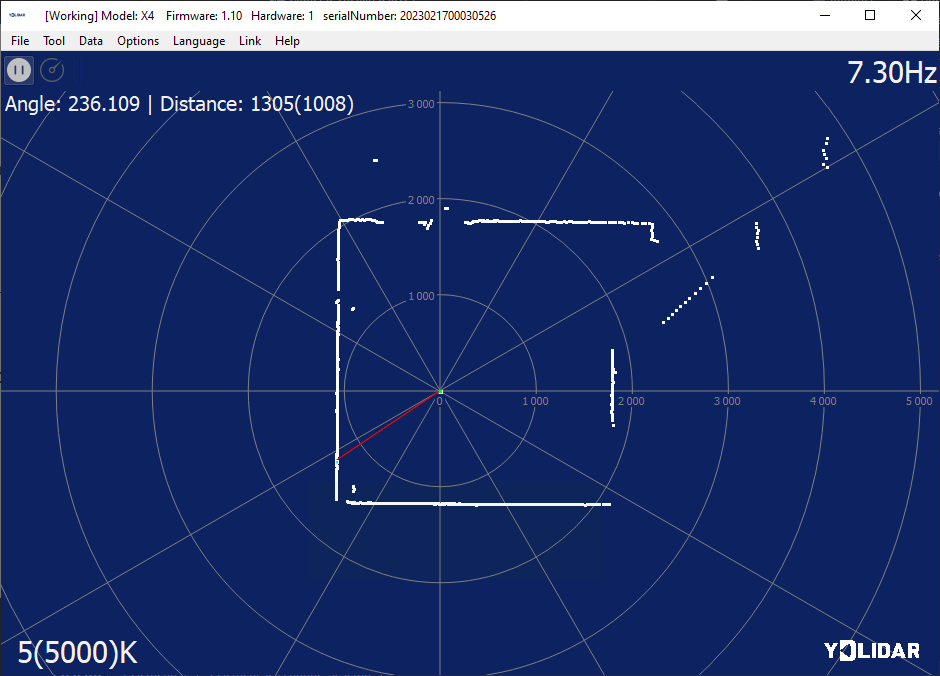
Uso de un sensor Lidar con Python
En este tutorial, veremos cómo configurar un mapa utilizando un sensor Lidar en Python. El sensor Lidar se utiliza para encontrar su orientación en el espacio y para mapear. Descripción del sensor Lidar El sensor lidar es un sensor láser de distancia acoplado a un...
Gestión de BLE en un ESP32 con MicroPython
,En este tutorial, aprenderemos a gestionar y probar la comunicación BLE (Bluetooth Low Energy) en un ESP32 usando MicroPython. Equipamiento Un módulo ESP32 Un ordenador con Python instalado Cable USB para conexión ESP32-ordenador Un dispositivo Android Configuración...
Creación de un Web Crawler con Python
Para recopilar datos en Internet, puedes crear un Web crawler o Web scraping con Python. Un rastreador web es una herramienta que extrae datos de una o varias páginas web. Configuración del entorno Python Asumimos que Python3 y pip están instalados en tu máquina....Productos
-
 Kit de robot Quadrina Servo MG90S
208,33€
Kit de robot Quadrina Servo MG90S
208,33€
-
 Archivo STL QuadrinaV1
1,50€
Archivo STL QuadrinaV1
1,50€
-
 Kit de robot Rovy para DC Motor TTGM
137,50€
Kit de robot Rovy para DC Motor TTGM
137,50€
-
 Kit de robot WillySR Servo FS90R
100,00€
Kit de robot WillySR Servo FS90R
100,00€
Licencia
![]()
Files are licensed under the Creative Commons – Attribution – Non-Commercial license