Pour entrainer un réseau de neurone à la détection et à la reconnaissance d’objet, il faut une banque d’image sur laquelle travailler. Nous allons voir comment télécharger un grand nombre d’images à partir de Google avec Python. Pour pouvoir entrainer un réseau de neurones, il est nécessaire d’avoir un grand nombre de données. Plus il y a de données, meilleur sera l’entrainement. Dans notre cas nous souhaitons entrainer un réseau de neurones à reconnaitre un objet en particulier. Pour cela, nous créons un script Python qui va venir télécharger les fichiers sur internet et les placer dans un dossier.
Configurer Python3
Téléchargez les librairies Selenium et OpenCV (optional)
python3 -m pip install selenium
python3 -m pip install opencv-pythonTéléchargez le fichier geckodriver, décompressez-le et copier le .EXE à l’endroit que vous voulez. Notez bien le chemin d’accès du fichier geckodriver.exe
N.B.: Nous n’utilisons la librairie OpenCV seulement pour vérifier que OpenCV peut ouvrir et utiliser les images afin de ne pas encombrer le dossier inutilement
Script Python de téléchargement d’image
Ce script lance une recherche sur Google Image et enregistre les images trouvées dans le dossier spécifié pour la banque d’images.
N.B.: N’oubliez pas de préciser le chemin du fichier geckodriver GECKOPATH, le chemin vers le dossier de destination et les mot-clés pour la recherche Google.
import sys
import os
import time
#Imports Packages
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import TimeoutException,WebDriverException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import cv2
########################################################################
GECKOPATH = "PATH-TO-GECKODRIVER"
parent_dir = "PATH-TO-FOLDER"
search='coffee mug'
########################################################################
# path
folderName=search.replace(" ","_")
directory = os.path.join(parent_dir, folderName,'img')
# Create the directory
try:
if not os.path.exists(directory):
os.makedirs(directory) #os.mkdir(directory)
except OSError as error:
print("ERROR : {}".format(error))
sys.path.append(GECKOPATH)
#Opens up web driver and goes to Google Images
browser = webdriver.Firefox()#Firefox(firefox_binary=binary)
#load google image
browser.get('https://www.google.ca/imghp?hl=en')
delay = 10 # seconds
try:
btnId="L2AGLb"
myElem = WebDriverWait(browser, delay).until(EC.presence_of_element_located((By.ID , btnId))) #id info-address-place-wrapper
#elm=browser.find_element_by_id(btnId)
elm=browser.find_element(By.ID,btnId)
elm.click()
print("Popup is passed!")
except TimeoutException as e:
print("Loading took too much time!")
time.sleep(30) #loading
# get and fill search bar
#box = browser.find_element_by_xpath('//*[@id="sbtc"]/div/div[2]/input')
#box = browser.find_element(By.XPATH,'//*[@id="sbtc"]/div/div[2]/input')
box = browser.find_element(By.TAG_NAME, "textarea")
box.send_keys(search)
box.send_keys(Keys.ENTER)
print("key enter is pressed")
time.sleep(10) #loading
#Will keep scrolling down the webpage until it cannot scroll no more
last_height = browser.execute_script('return document.body.scrollHeight')
while True:
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(20)
new_height = browser.execute_script('return document.body.scrollHeight')
try:
#browser.find_element_by_xpath('//*[@id="islmp"]/div/div/div/div/div[5]/input').click()
browser.find_element(By.XPATH,'//*[@id="islmp"]/div/div/div/div/div[5]/input').click()
time.sleep(10)
except:
print("button not found")
pass
if new_height == last_height:
break
last_height = new_height
#find all images on page
imgList=[]
try:
#imgs = browser.find_elements(By.TAG_NAME, "img")
#imgs = browser.find_elements(By.CLASS_NAME, "rg_i")
imgs = browser.find_elements(By.XPATH,"//img[contains(@class,'rg_i')]")
print("found {} images".format(len(imgs)))
for i,img in enumerate(imgs):
#src=img.get_attribute("src") # get source of image
#urllib.request.urlretrieve(str(src),directory+"\{}.png".format(i)) # download source
img.screenshot(directory+'\{}.png'.format(i)) # or screenshot
imgList.append(directory+'\{}.png'.format(i))
except:
print("imagenot found")
pass
browser.quit()
#Test images with OpenCV
for img in imgList:
try:
cv2.imread(img)
except Exception as e:
os.remove(img)
print("remove {}".format(img))
N.B.: update avec nouvelle version de selenium find_element_by_id(thisId) –> find_element(By.Id,thisId)
BONUS: Gestion d’une popup
Dans le code j’ai rajouté une commande permettant de gérer la popup qui apparait à l’ouverture de la page internet. Il va attendre que le bouton avec le bon identifiant soit chargé avant d’appuyer dessus.
delay = 10 # seconds
try:
btnId="L2AGLb"
myElem = WebDriverWait(browser, delay).until(EC.presence_of_element_located((By.ID , btnId))) #id info-address-place-wrapper
elm=browser.find_element_by_id(btnId)
elm.click()
print("Popup is passed!")
except TimeoutException as e:
print("Loading took too much time!")
Résultat
Le script va parcourir les résultats de Google et faire des captures d’écran de chaque image pour les placer dans notre base de données et former une banque d’images.
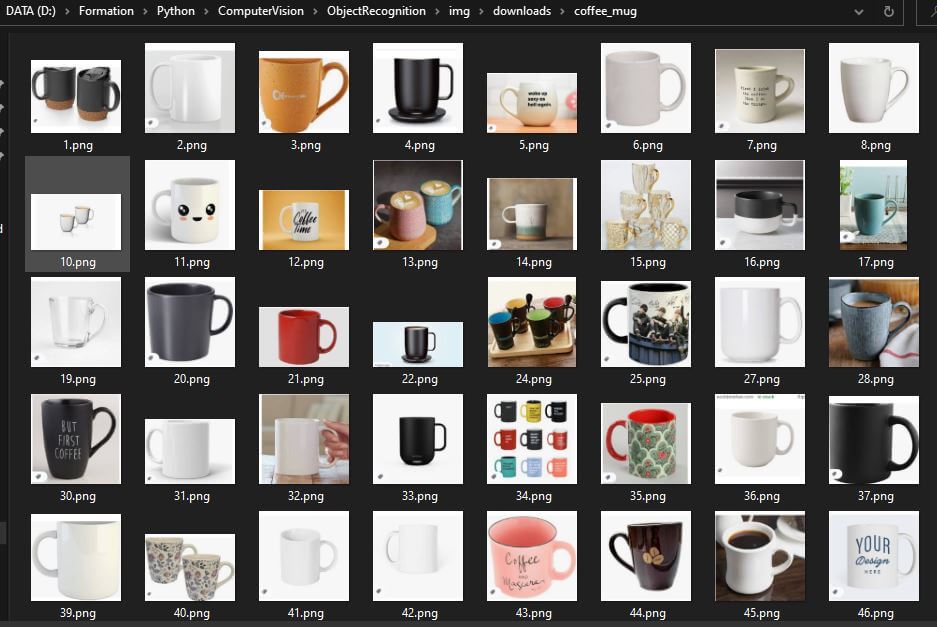
Vous avez désormais une banque d’image que vous pouvez utiliser pour de la reconnaissance visuelle par exemple ou faire du traitement d’image.
Applications
- Développer des algorithmes de traitement d’image
- Entrainer des réseaux de neurones à la détection et reconnaissance d’objet




Bonjour Monsieur!
Merci beaucoup pour votre code car je suis arrivé à avoir une banque d’images: les nids de poule (pothole) au nombre de 49.
Je voudrais d’abord savoir si ce nombre est bon pour un modèle? et
Deuxièmement je voudrais savoir si vous pouvez me donner un script python ou autre indication pour me permettre d’entrainer mon modèle pour avoir le même résultat(fichier prototxt et le fichier caffemodel) que vous avez obtenus dans votre tutoriel précédent sur Reconnaissance d’Objet avec Python avec les bateaux?
Pardon au secours pour me permettre de réaliser mon projet.