, ,
Para entrenar una red neuronal en detección y reconocimiento de objetos, se necesita un banco de imágenes con el que trabajar. Veremos cómo descargar un gran número de imágenes de Google utilizando Python. Para entrenar una red neuronal, necesitas una gran cantidad de datos. Cuantos más datos, mejor será el entrenamiento. En nuestro caso, queremos entrenar una red neuronal para que reconozca un objeto concreto. Para ello, creamos un script en Python que descargará los archivos de Internet y los colocará en una carpeta.
Configuración de Python3
Descargar las bibliotecas Selenium y OpenCV (opcional)
python3 -m pip install selenium
python3 -m pip install opencv-pythondescargar archivo geckodriver
N.B.: Sólo utilizamos la librería OpenCV para comprobar que OpenCV puede abrir y utilizar las imágenes, para no saturar innecesariamente la carpeta.
Script en Python para descargar imágenes
Este script lanza una búsqueda en Google Image y guarda las imágenes encontradas en la carpeta especificada para el banco de imágenes.
N.B.: No olvide especificar la ruta al archivo GECKOPATH de geckodriver, la ruta a la carpeta de destino y las palabras clave para la búsqueda en Google.
import sys
import os
import time
#Imports Packages
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import TimeoutException,WebDriverException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import cv2
########################################################################
GECKOPATH = "PATH-TO-GECKODRIVER"
parent_dir = "PATH-TO-FOLDER"
search='coffee mug'
########################################################################
# path
folderName=search.replace(" ","_")
directory = os.path.join(parent_dir, folderName,'img')
# Create the directory
try:
if not os.path.exists(directory):
os.makedirs(directory) #os.mkdir(directory)
except OSError as error:
print("ERROR : {}".format(error))
sys.path.append(GECKOPATH)
#Opens up web driver and goes to Google Images
browser = webdriver.Firefox()#Firefox(firefox_binary=binary)
#load google image
browser.get('https://www.google.ca/imghp?hl=en')
delay = 10 # seconds
try:
btnId="L2AGLb"
myElem = WebDriverWait(browser, delay).until(EC.presence_of_element_located((By.ID , btnId))) #id info-address-place-wrapper
elm=browser.find_element_by_id(btnId)
elm.click()
print("Popup is passed!")
except TimeoutException as e:
print("Loading took too much time!")
# get and fill search bar
box = browser.find_element_by_xpath('//*[@id="sbtc"]/div/div[2]/input')
box.send_keys(search)
box.send_keys(Keys.ENTER)
#Will keep scrolling down the webpage until it cannot scroll no more
last_height = browser.execute_script('return document.body.scrollHeight')
while True:
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(5)
new_height = browser.execute_script('return document.body.scrollHeight')
try:
browser.find_element_by_xpath('//*[@id="islmp"]/div/div/div/div/div[5]/input').click()
time.sleep(5)
except:
print("button not found")
pass
if new_height == last_height:
break
last_height = new_height
imgList=[]
for i in range(1, 1000):
try:
browser.find_element_by_xpath('//*[@id="islrg"]/div[1]/div['+str(i)+']/a[1]/div[1]/img').screenshot(directory+'\{}.png'.format(i))
imgList.add(directory+'\{}.png'.format(i))
except:
pass
browser.quit()
#Test images with OpenCV
for img in imgList:
try:
cv2.imread(img)
except Exception as e:
os.remove(img)
print("remove {}".format(img))
BONUS: Gestión de una ventana emergente
En el código he añadido un comando para gestionar la ventana emergente que aparece al abrir la página web. Esperará a que se cargue el botón con el identificador correcto para pulsarlo.
delay = 10 # seconds
try:
btnId="L2AGLb"
myElem = WebDriverWait(browser, delay).until(EC.presence_of_element_located((By.ID , btnId))) #id info-address-place-wrapper
elm=browser.find_element_by_id(btnId)
elm.click()
print("Popup is passed!")
except TimeoutException as e:
print("Loading took too much time!")
Resultados
El script recorrerá los resultados de Google y tomará capturas de pantalla de cada imagen para colocarlas en nuestra base de datos y formar un banco de imágenes.
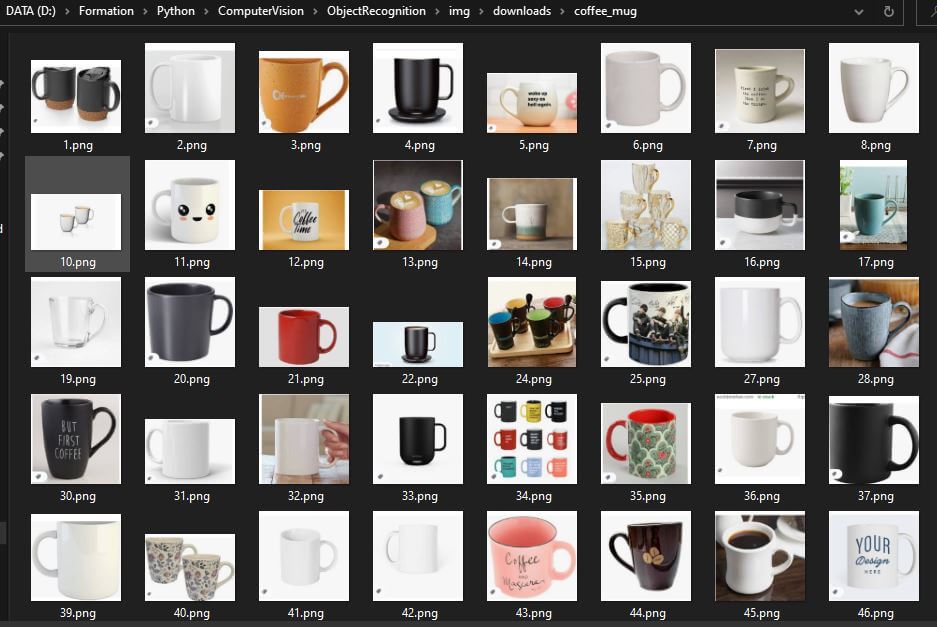
Aplicaciones
- Desarrollar algoritmos de tratamiento de imágenes
- Entrenamiento de redes neuronales para la detección y el reconocimiento de objetos



