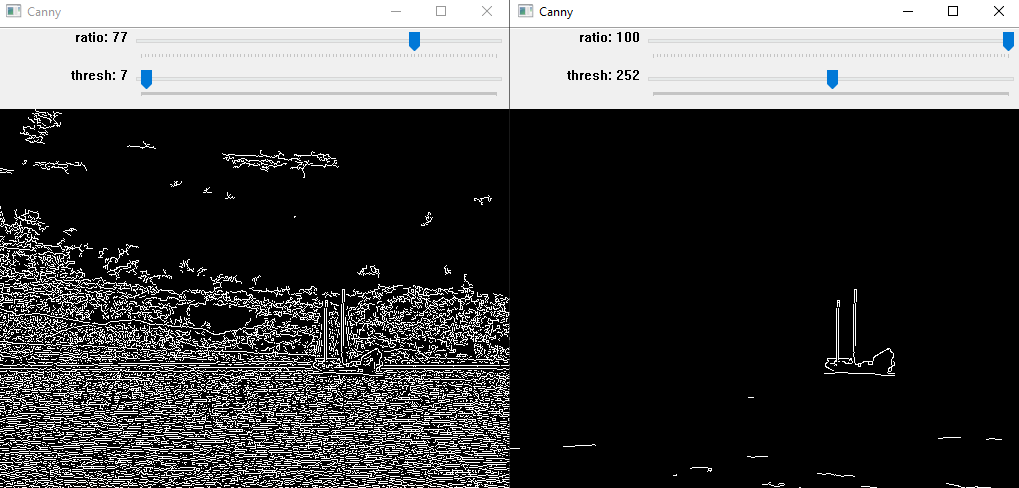
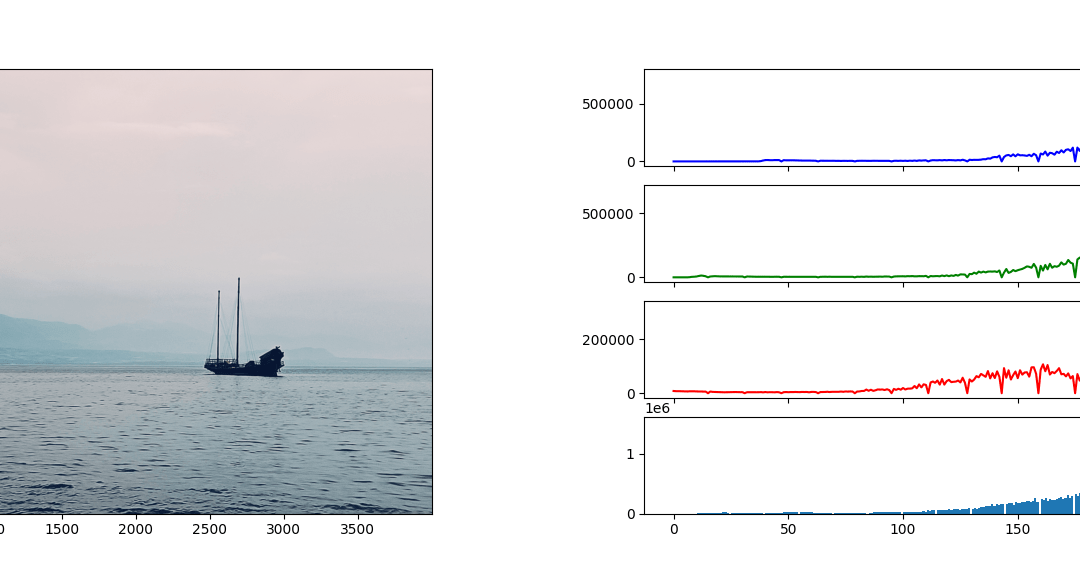
Traitement d’image avec OpenCV et Python
Le module open-source OpenCV est un outil puissant de traitement d’image contenant des algorithmes de vision par ordinateur. Ce module est codé nativement en C++ mais une API est disponible sur Python. On l’utilise pour le traitement d’image, photo...
Filtrer les couleurs avec OpenCV et Python
Lors de traitement d’image, il peut être intéressant de filtrer une couleur pour la modifier, la garder ou la supprimer. Nous allons voir dans ce tutoriel comment sélectionner et filtrer une zone de couleur avec OpenCV et Python. Traitement d’image Pour ce...Reconnaissance d’objets avec Yolo et OpenCV
Nous allons voir dans ce tutoriel comment faire de la reconnaissance d’objet avec Yolo et OpenCV en utilisant un réseau de neurones pré-entrainé grâce au deep learning. Nous avons vu dans un précédent tutoriel comment reconnaitre des formes simples avec la...
Reconnaissance de texte avec Python
Nous allons voir dans ce tutoriel comment faire de la reconnaissance de texte à partir d’une image avec Python et Tesseract. Tesseract est un outil permettant de reconnaitre des caractères, et donc du texte, contenus dans une image (OCR, Optical Characters...Produits
-
 Moteur CC TT avec réducteur double-axe DG01D
3,00€
Moteur CC TT avec réducteur double-axe DG01D
3,00€
-
 Kit Arduino pour débutant
82,50€
Kit Arduino pour débutant
82,50€
-
 Ordinateur monocarte Rock Pi 4 SE 4 Go
85,00€
Ordinateur monocarte Rock Pi 4 SE 4 Go
85,00€
-
 Support servomoteur horizontal
Gratuit
Support servomoteur horizontal
Gratuit
-
 Fichier STL WillySR
Gratuit
Fichier STL WillySR
Gratuit
Licence
![]()
Files are licensed under the Creative Commons – Attribution – Non-Commercial license