
Reconocimiento de textos con Python
En este tutorial veremos cómo reconocer texto de una imagen utilizando Python y Tesseract. Tesseract es una herramienta para reconocer caracteres, y por tanto texto, contenidos en una imagen (OCR, Optical Character Recognition). Instalación de Tesseract En Linux Para...
Visualización de una imagen OpenCV en una interfaz PyQt
Para ciertas aplicaciones, puede resultarte útil incrustar OpenCV en una interfaz PyQt. En este tutorial, veremos cómo integrar y gestionar correctamente un vídeo capturado por OpenCV en una aplicación PyQt. N.B.: Utilizamos Pyside, pero la conversión a PyQt es...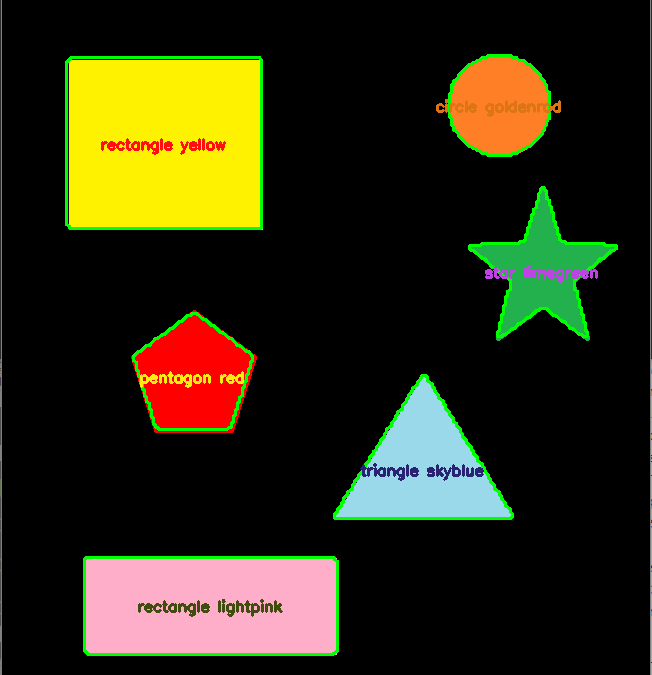
Reconocimiento de formas y colores con Python
, La biblioteca OpenCV se utiliza para el procesamiento de imágenes, en particular el reconocimiento de formas y colores. La biblioteca tiene funciones de adquisición y algoritmos de procesamiento de imágenes que hacen que el reconocimiento de imágenes sea bastante...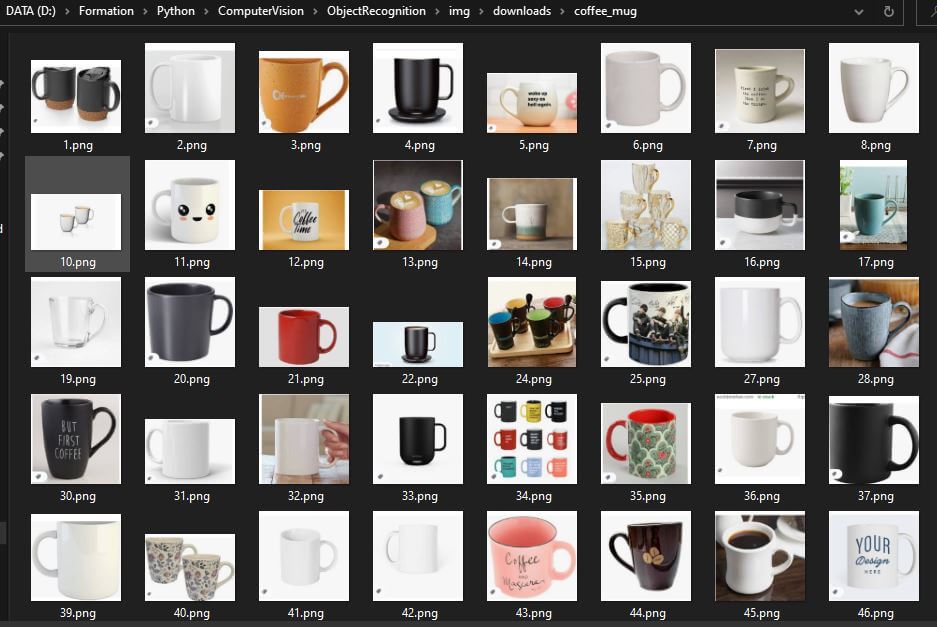
Crear un banco de imágenes con Python
, , Para entrenar una red neuronal en detección y reconocimiento de objetos, se necesita un banco de imágenes con el que trabajar. Veremos cómo descargar un gran número de imágenes de Google utilizando Python. Para entrenar una red neuronal, necesitas una gran...Productos
-
 Kit de robot Quadrina Servo MG90S
208,33€
Kit de robot Quadrina Servo MG90S
208,33€
-
 Archivo STL QuadrinaV1
1,50€
Archivo STL QuadrinaV1
1,50€
-
 Kit de robot Rovy para DC Motor TTGM
137,50€
Kit de robot Rovy para DC Motor TTGM
137,50€
-
 Kit de robot WillySR Servo FS90R
100,00€
Kit de robot WillySR Servo FS90R
100,00€
Licencia
![]()
Files are licensed under the Creative Commons – Attribution – Non-Commercial license