
Text recognition with Python
In this tutorial, we’ll look at how to recognize text from images using Python and Tesseract. Tesseract is a tool for recognizing characters, and therefore text, contained in an image (OCR, Optical Character Recognition). Installing Tesseract Under Linux To...
Displaying an OpenCV Image in a PyQt interface
For certain applications, you may find it useful to embed OpenCV in a PyQt interface. In this tutorial, we’ll look at how to correctly integrate and manage a video captured by OpenCV in a PyQt application. N.B.: We use Pyside, but conversion to PyQt is quite...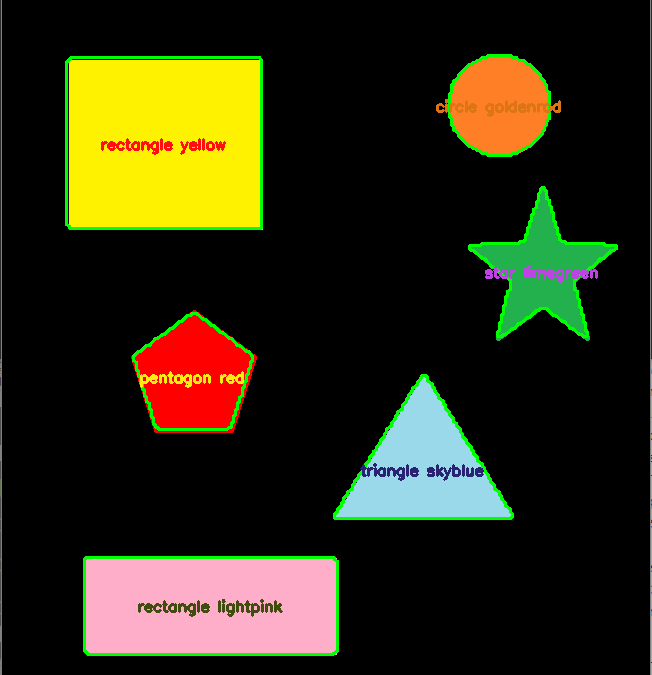
Shape and color recognition with Python
, The OpenCV library is used for image processing, in particular shape and color recognition. The library has acquisition functions and image processing algorithms that make image recognition fairly straightforward, without the need for artificial intelligence. This...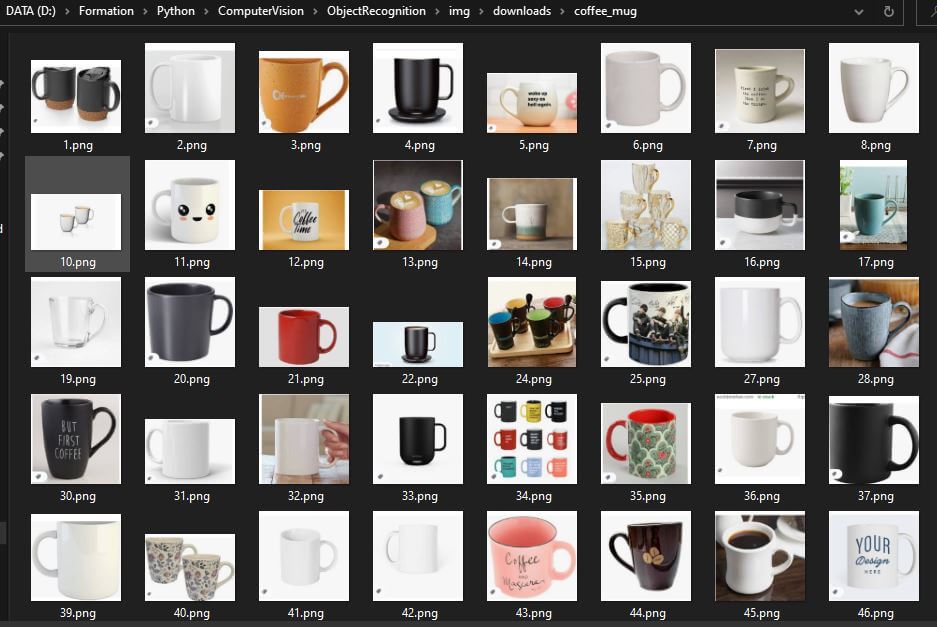
Create your image bank with Python
, , To train a neural network in object detection and recognition, you need an image bank to work with. We’ll see how to download a large number of images from Google using Python. To train a neural network, you need a large amount of data. The more data, the...Products
-
 Robotic kit Quadrina Servo MG90S
208.33€
Robotic kit Quadrina Servo MG90S
208.33€
-
 STL file QuadrinaV1
1.50€
STL file QuadrinaV1
1.50€
-
 Robotic kit Rovy for DC Motor TTGM
137.50€
Robotic kit Rovy for DC Motor TTGM
137.50€
-
 Robotic kit WillySR Servo FS90R
100.00€
Robotic kit WillySR Servo FS90R
100.00€
License
![]()
Files are licensed under the Creative Commons – Attribution – Non-Commercial license