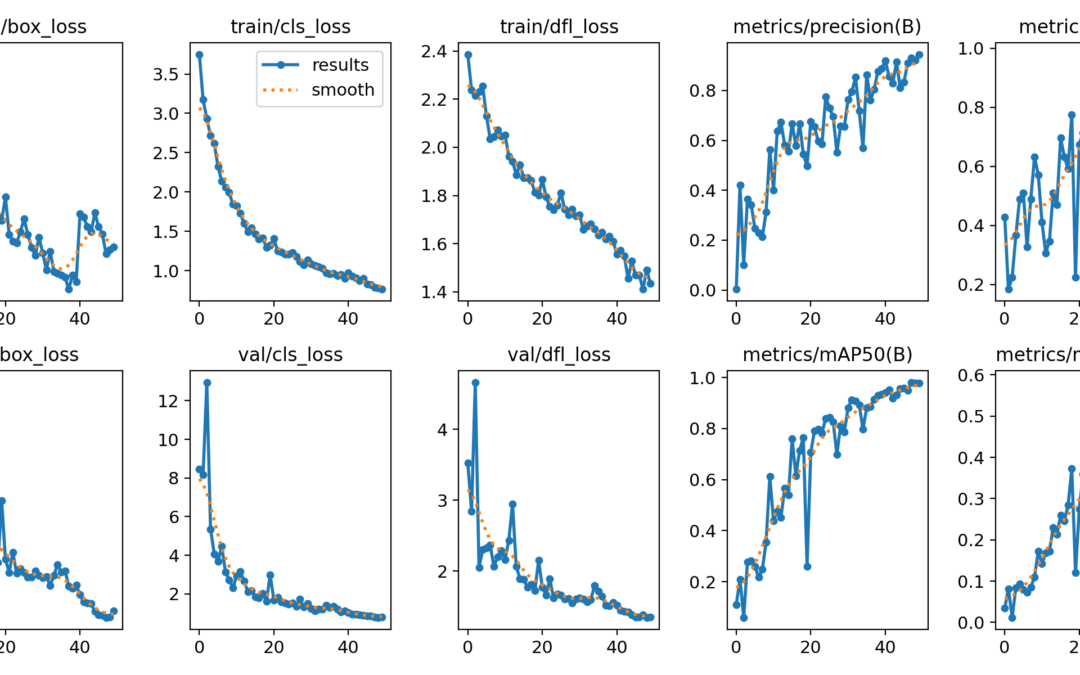
Training a Yolo model
In this tutorial, we’ll look at how to train a YOLO model for object recognition on specific data. The difficulty lies in creating the image bank that will be used for training. Hardware A computer with a Python3 installation A camera Principle We saw in a...
Raspberry Pi object detection and TensorFlow Lite
To improve performance on the Raspberry Pi, you can use the C++ language and optimized libraries to accelerate the computation speed of object detection models. This is what TensorFlow Lite offers. A good place to start is QEngineering. Hardware Raspberry Pi 4...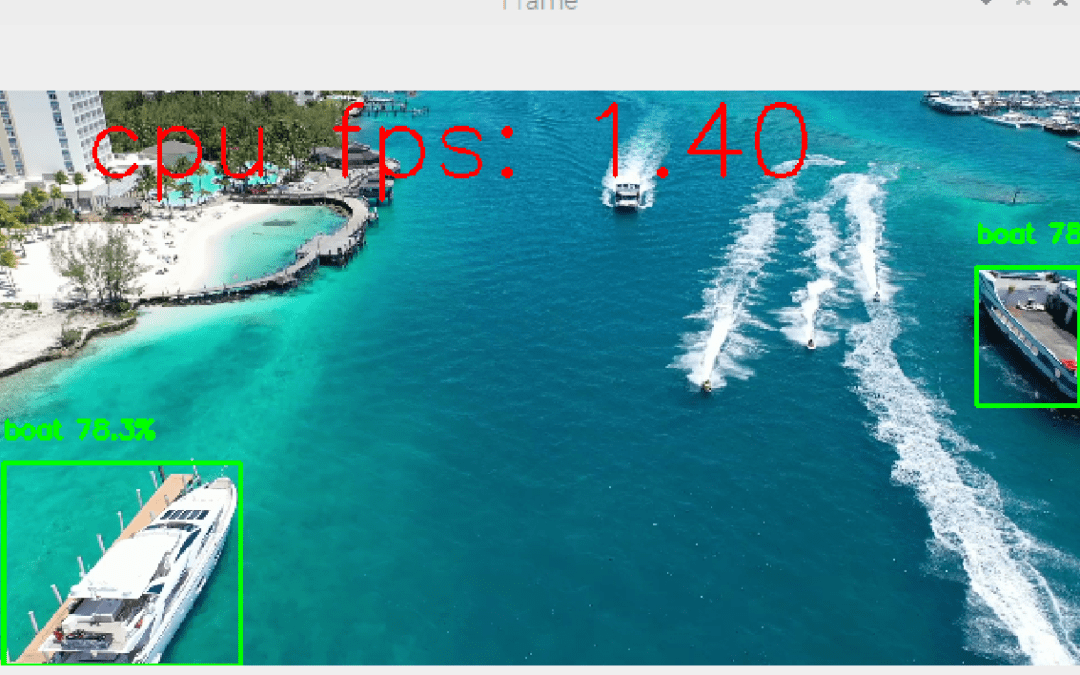
Object detection with Yolo on Raspberry Pi
It’s possible to embed object recognition models like Yolo on a Raspberry Pi. Of course, because of its low performance compared with computers, performance is lower in terms of real-time recognition. However, it is perfectly possible to develop algorithms using...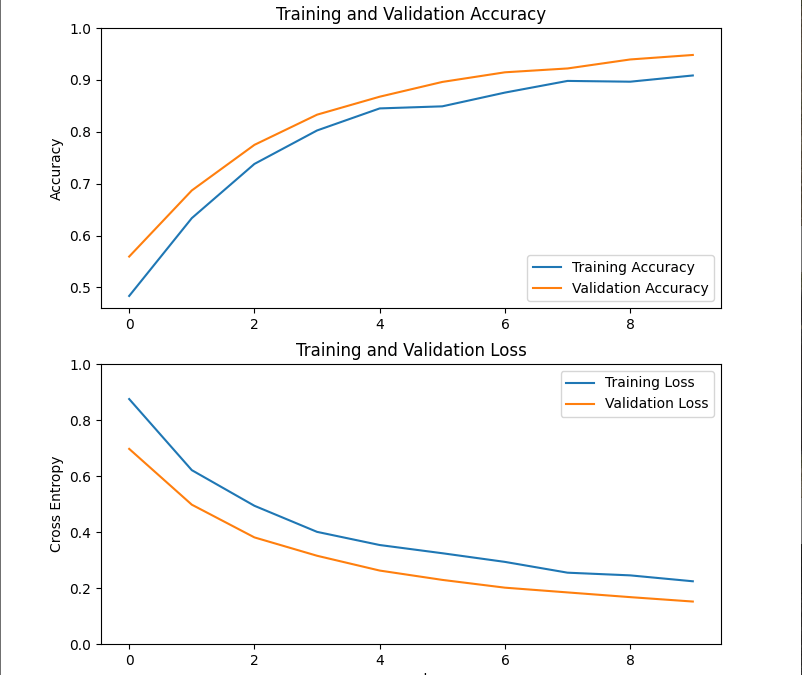
Training a TensorFlow2 model with Keras
In this tutorial, we’ll train a MobileNetV2 TensorFlow model with Keras so that it can be applied to our problem. We’ll then be able to use it in real time to classify new images. For this tutorial, we assume that you have followed the previous tutorials:...Products
-
 Robotic kit Quadrina Servo MG90S
208.33€
Robotic kit Quadrina Servo MG90S
208.33€
-
 STL file QuadrinaV1
1.50€
STL file QuadrinaV1
1.50€
-
 Robotic kit Rovy for DC Motor TTGM
137.50€
Robotic kit Rovy for DC Motor TTGM
137.50€
-
 Robotic kit WillySR Servo FS90R
100.00€
Robotic kit WillySR Servo FS90R
100.00€
License
![]()
Files are licensed under the Creative Commons – Attribution – Non-Commercial license