Neste tutorial, vamos ver como treinar um modelo YOLO para reconhecimento de objectos em dados específicos. A dificuldade reside na criação do banco de imagens que será utilizado para o treino.
Hardware
- Um computador com uma instalação Python3
- Uma câmara
Princípio
Vimos num tutorial anterior como reconhecer objectos com o Yolo. Este modelo foi treinado para detetar um certo número de objectos, mas esta lista é limitada.
{0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus', 6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant', 11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat', 16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear', 22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag', 27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard', 32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove', 36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle', 40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl', 46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli', 51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake', 56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table', 61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard', 67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink', 72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors', 77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'}
O modelo pode ser treinado para reconhecer objectos adicionais ou outros objectos utilizando um banco de imagens adequado.
Configurar o Python
Caso contrário, pode descarregar e instalar o Python 3
Pode então instalar as bibliotecas necessárias: imutils, OpenCV, ultralytics, etc.
python3 -m pip install imutils opencv-python ultralytics
Configuração de dados
Depois de ter criado uma base de dados de imagens com etiquetas e caixas no formato Yolo, coloque a base de dados na pasta YOLO\datasets. Em seguida, pode resumir as informações num ficheiro YAML que especifica:
- o caminho para a base de dados contida nos conjuntos de dados (coffe_mug)
path: coffee_mug/ train: 'train/' val: 'test/' # class names names: 0: 'mug'
N.B.: pode passar caminhos de acesso como directórios de imagens, ficheiros de texto (caminho
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: [./coco128/images/train2017/, coffee_mug/test/]
val: [./coco128/images/train2017/, coffee_mug/train/]
# class names
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush', 'mug']
Recuperar um modelo pré-treinado
É possível obter um modelo pré-treinado a partir do script python, que será utilizado como base para treinar o novo modelo.
# load the pre-trained YOLOv8n model
model = YOLO("yolov8n.pt")
N.B.: verifique atentamente o modelo que corresponde à sua máquina e às suas necessidades, uma vez que têm níveis de desempenho diferentes.
Script Python para treinar o Yolo
Quando o banco de imagens estiver pronto, o guião de formação é bastante simples. Tudo o que tem de fazer é especificar:
- o nome do novo modelo (yolov8n_v8_50e)
- o número de iterações (épocas)
- a base de dados a utilizar (dados)
- o número de ficheiros a utilizar numa iteração (lote)
treinar_yolo.py
from ultralytics import YOLO
# Load the model.
model = YOLO('yolov8n.pt')
# Training.
results = model.train(
data='coffee_mug_v8.yaml',
imgsz=1280,
epochs=50,
batch=8,
name='yolov8n_v8_50e'
)
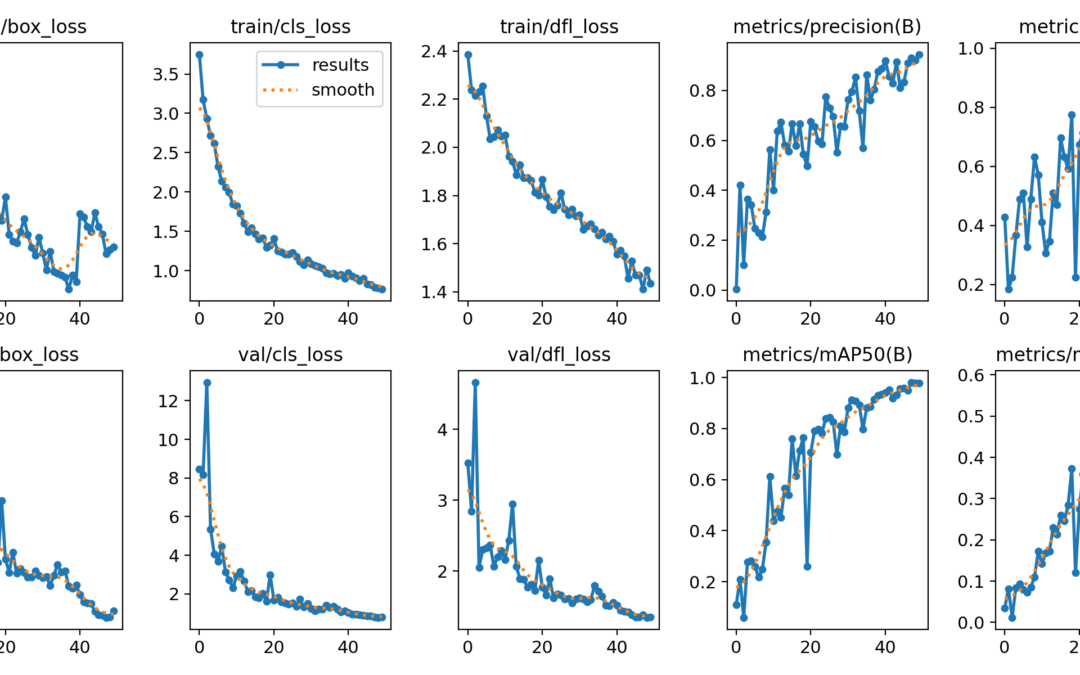
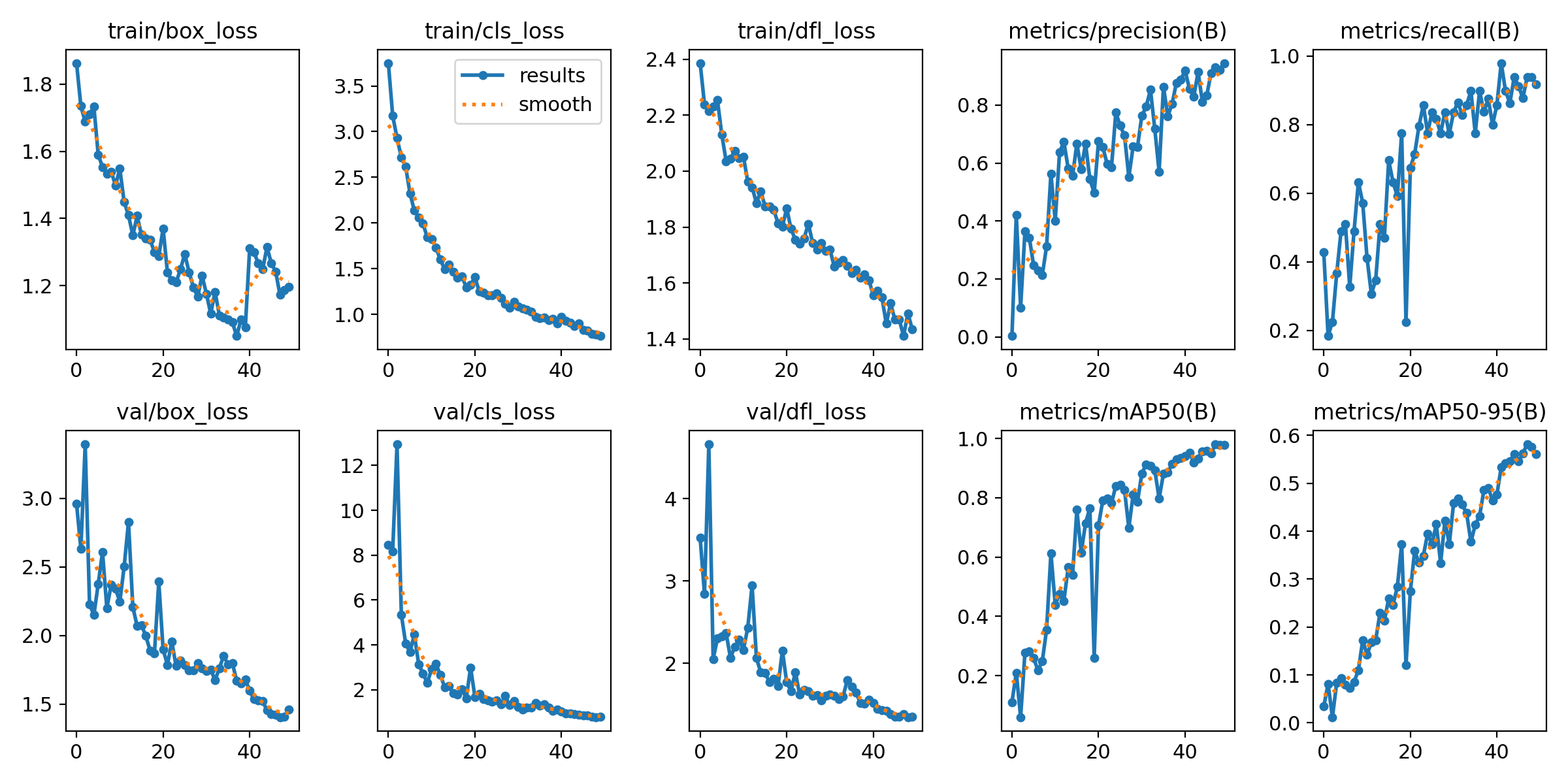
O algoritmo de treino regista uma certa quantidade de dados durante o processo, que pode ver posteriormente para analisar o treino. Os resultados podem ser encontrados na pasta .\runs\detect\.
Script Python para avaliação de modelos
Depois de o modelo ter sido treinado, pode comparar o seu desempenho com novas imagens.
Para recuperar o modelo treinado, pode copiá-lo para a raiz ou introduzir o caminho de acesso
“./runs/detect/yolov8n_v8_50e2/weights/best.pt”
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
import datetime
from ultralytics import YOLO
import cv2
from imutils.video import VideoStream
#from helper import create_video_writer
# define some constants
CONFIDENCE_THRESHOLD = 0.65
GREEN = (0, 255, 0)
image_list=['./datasets/coffee_mug/test/10.png','./datasets/coffee_mug/test/19.png']
# load the pre-trained YOLOv8n model
#model = YOLO("yolov8n.pt")
model = YOLO("./runs/detect/yolov8n_v8_50e2/weights/best.pt") # test trained model
for i,img in enumerate(image_list):
#detect on image
frame= cv2.imread(img)#from image file
detections = model(frame)[0]
# loop over the detections
#for data in detections.boxes.data.tolist():
for box in detections.boxes:
#extract the label name
label=model.names.get(box.cls.item())
# extract the confidence (i.e., probability) associated with the detection
data=box.data.tolist()[0]
confidence = data[4]
# filter out weak detections by ensuring the
# confidence is greater than the minimum confidence
if float(confidence) < CONFIDENCE_THRESHOLD:
continue
# if the confidence is greater than the minimum confidence,
# draw the bounding box on the frame
xmin, ymin, xmax, ymax = int(data[0]), int(data[1]), int(data[2]), int(data[3])
cv2.rectangle(frame, (xmin, ymin) , (xmax, ymax), GREEN, 2)
#draw confidence and label
y = ymin - 15 if ymin - 15 > 15 else ymin + 15
cv2.putText(frame, "{} {:.1f}%".format(label,float(confidence*100)), (xmin, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, GREEN, 2)
# show the frame to our screen
cv2.imshow("Img{}".format(i), frame)
while True:
if cv2.waitKey(1) == ord("q"):
break
Resultados
O objetivo é alcançado porque obtemos um novo modelo que reconhece apenas as canecas ({0: ‘mug’}).
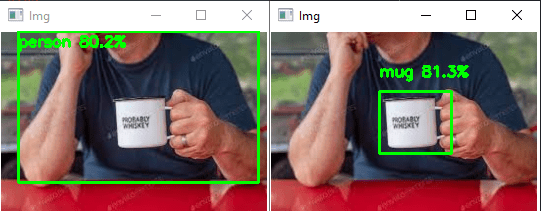
Pode testar este código com a sua webcam ou com fotografias, por exemplo, para ver o desempenho do modelo e do reconhecimento de objectos.
Para que o modelo possa reconhecer mais tipos de objectos, é necessário adicionar imagens do objeto em questão à base de dados.