

Créer un script Python sous ROS2
Dans ce tutoriel, nous allons voir comment créer et lancer des script Python sous ROS2. Vous pourrez ainsi créer vos propres noeuds et commencer à développer sous ROS. Créer un espace de travail Une bonne pratique pour développer sous ROS2 est de créer des workspaces...
Installer ROS2 sur Raspberry Pi
Dans ce tutoriel, nous allons voir comment installer ROS2 sur une machine Linux et notamment un Raspberry Pi 4 avec une distribution Ubuntu. ROS2 est un framework intéressant à abordé lorsqu’on travaille sur des systèmes embarqués comme les robots. Matériel...
Envoyer de longues chaînes de caractères via BLE
Le Bluetooth Low Energy (BLE) a une limitation connue d’une 20Bytes pour la longueur des chaînes envoyées. Ils existent des méthodes pour outrepasser cette limite. Matériel Dans ce tutoriel, nous envoyons des données à partir d’une application Android,...
Donner la parole à votre appareil Android avec React Native TTS
Nous allons voir dans ce tutoriel comment donner la parole à votre appareil Android avec une librairie Text to Speech (TTS). Que ce soit pour développer des applications pour malvoyant ou pour donner plus de vie à votre système Android, donner la parole à votre projet...
Créer un composant fonctionnel avec React Native
Afficher un Stream Vidéo Motion sur React Native
Nous allons voir dans ce tutoriel comment récupérer un flux vidéo Motion sur une application React Native. Configuration du projet Nous avons mis en place un stream vidéo avec Motion sur une machine Linux dont l’adresse est 192.168.1.92:8554 sur le réseau Wifi....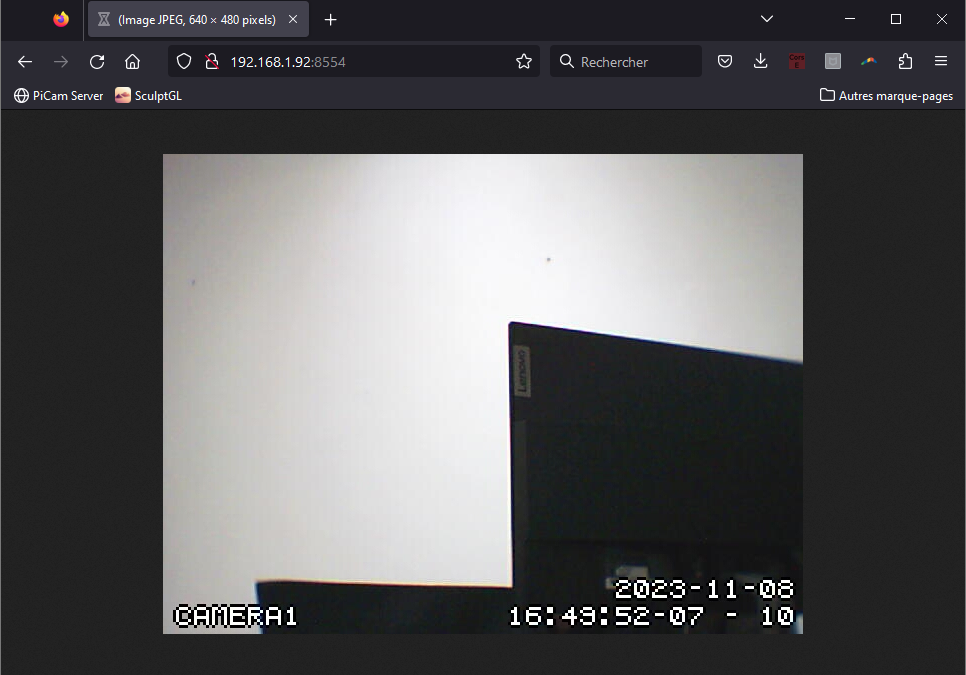
Vidéo stream avec Motion sur Raspberry Pi
Nous allons voir dans ce tutoriel comment mettre en place un stream vidéo avec Motion à partir d’un Raspberry Pi. Ce tutoriel reste compatible avec tout système Linux. Matériel Raspberry Pi (ou autre machine linux) Caméra USB ou Caméra CSI Description de Motion...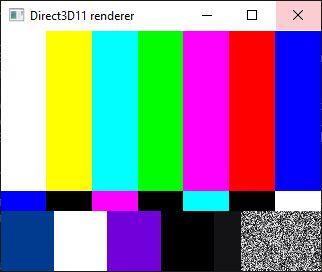
Vidéo stream avec Gstreamer sur Raspberry Pi
Nous allons voir dans ce tutoriel comment streamer un flux vidéo à partir d’un Raspberry Pi avec Gstreamer. Un des outils de streaming les plus utilisé est FFMPEG. Nous testons ici, gstreamer car il y a moins de délai de transmission. Précédent tutoriel de...
Premier pas avec Android sur Rock Pi 4
La carte Rock Pi 4 de chez Radxa peut tourner avec un OS Debian, Ubuntu ou Android. Nous allons voir dans ce tutoriel comment configurer et utiliser votre micro-ordinateur avec Android. Matériel Rock Pi 4 SE Carte SD 32 Go Un écran HDMI Clavier+souris Câble USB A vers...Produits
-
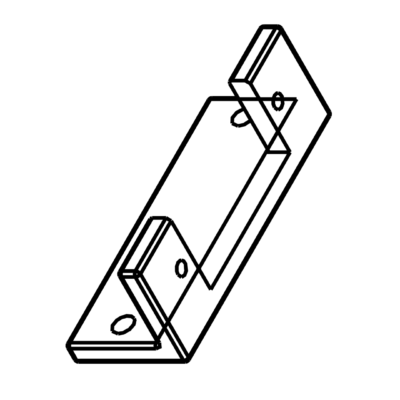 Support servomoteur lateral
Gratuit
Support servomoteur lateral
Gratuit
-
 Fichier STL Rovy
Gratuit
Fichier STL Rovy
Gratuit
-
 Robot en kit Quadrina pour Servomoteur MG90S
208,33€
Robot en kit Quadrina pour Servomoteur MG90S
208,33€
-
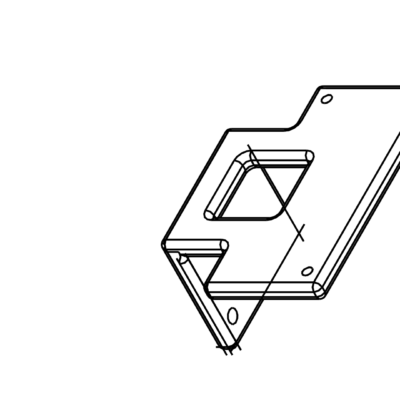 Support capteur V1
Gratuit
Support capteur V1
Gratuit
-
 Microcontrôleur Arduino Mega 2560 Rev3
35,00€
Microcontrôleur Arduino Mega 2560 Rev3
35,00€
Licence
![]()
Files are licensed under the Creative Commons – Attribution – Non-Commercial license