To collect data on the Internet, you can create a Web crawler or Web scraping program with Python. A web crawler is a tool that extracts data from one or more web pages.
Configuring the Python environment
We assume that Python3 and pip are installed on your machine. You can also use a virtual environment to keep your project clean and control the library versions of your Python web crawler.
First of all, we’re going to install the requests library, which enables HTTP requests to be made to the server to retrieve data.
python -m pip install requests
To analyze and navigate Web data, we use the Beautiful Soup library, which allows us to work with tag-based scripts such as HTML or XML.
python -m pip install beautifulsoup4
Finally, we install the Selenium library, which automates web browser tasks. It can display dynamic web pages and perform actions on the interface. This library alone can be used for web scraping on the Internet, as it can work with a dynamic website running JavaScript.
python -m pip install selenium
To run Selenium with Mozilla, you will need to download Geckodriver
Recovering a Web page with resquest
If we want to retrieve technical data from an Arduino board, we can load the desired page with requests and bs4
page = requests.get("https://docs.arduino.cc/hardware/uno-rev3/")
content = BeautifulSoup(page.text, 'html.parser')
By observing the page structure, you can locate the tags, classes, identifiers or texts that interest you. In this example, we retrieve
- card name
- card description
N.B.: You can view the structure of the web page in your browser by right-clicking on the page and selecting “Inspect”.
import requests
from bs4 import BeautifulSoup
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#google search
#keywords = ["arduino","datasheet"]
#googlesearch = "https://www.google.com/search?client=firefox-b-d&q="
#search = "+".join(keywords)
#website = googlesearch+search
# get page
page = requests.get(website)
#extract html data
content = BeautifulSoup(page.text, 'html.parser')
# extract tags
h1_elms = content.find_all('h1')
print("Board : ",h1_elms)
#get element by class
description = content.find(class_="product-features__description").text
print("Description : ",description)
Starting Web Crawling ... Board : [<h1>UNO R3</h1>] Description : Arduino UNO is a microcontroller board based on the ATmega328P. It has 14 digital input/output pins (of which 6 can be used as PWM outputs), 6 analog inputs, a 16 MHz ceramic resonator, a USB connection, a power jack, an ICSP header and a reset button. It contains everything needed to support the microcontroller; simply connect it to a computer with a USB cable or power it with a AC-to-DC adapter or battery to get started. You can tinker with your UNO without worrying too much about doing something wrong, worst case scenario you can replace the chip for a few dollars and start over again.
We could imagine looping this operation around a list of URLs for several cards.
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
With this method, we unfortunately can’t load the detailed list of “Tech Specs”, so we have to use the browser.
Setting up a Web Crawler with Selenium
Loading a page is easy
from selenium import webdriver
GECKOPATH = "PATH_TO_GECKO"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
#website to crawl
website="https://docs.arduino.cc/hardware/uno-rev3/"
#create browser handler
browser = webdriver.Firefox()
browser.get(website)
#browser.quit()
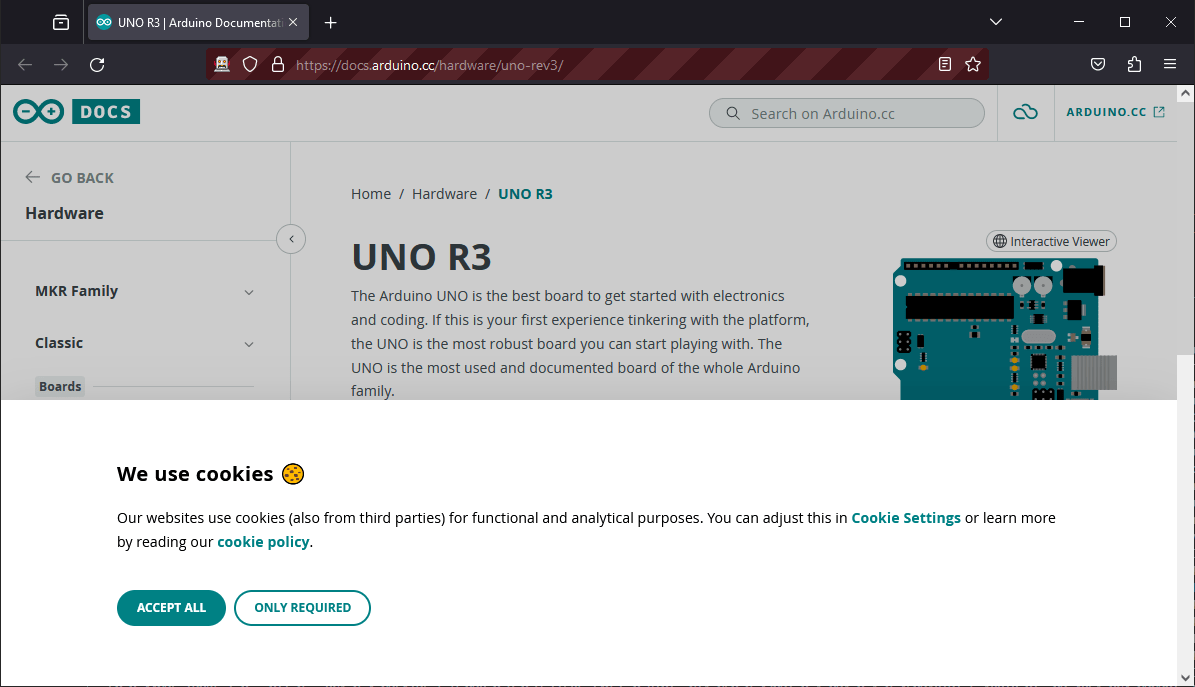
Cookie validation
When the page is displayed, you’re likely to come across the cookie banner, which you’ll need to accept or reject in order to continue browsing. To do this, find and click on the “accept” button.
def acceptcookies(): """class="iubenda-cs-accept-btn iubenda-cs-btn-primary""" browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click() acceptcookies()
Waiting to load
As the page is displayed in the browser, it takes some time for it to load the data and for all the tags to be displayed. To wait for loading, you can wait an arbitrary amount of time
browser.implicitly_wait(10)
Or wait until a particular tag is present, such as the cookie acceptance button
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)
N.B: If you encounter any other problems (unknown element, non-clickable button, etc.) in the script when there are no problems on the Web page, don’t hesitate to use the time.sleep() function.
Find and press a DOM element
To display the technical specifications, the script must click on the ‘Tech Specs’ tab. This means finding the element from the text. There are two ways to do this: test the element text or use Xpath
#get element by text
btn_text = 'Tech Specs'
btn_elms = browser.find_elements(By.CLASS_NAME,'tabs')[0].find_elements(By.TAG_NAME,'button')
for btn in btn_elms:
if btn.text == btn_text:
btn.click()
spec_btn = browser.find_element(By.XPATH, "//*[contains(text(),'Tech Specs')]")
spec_btn.click()
Retrieve the desired data
Once the desired page has been loaded, you can retrieve the data.
All data displayed in table form
#get all rows and children
print("Tech specs")
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)
Either specific data
#get parent and siblings
print("Specific data")
print("-------------------------------------")
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)
Result of specification crawling
Starting Web Crawling ... Page is ready! Tech specs ------------------------------------- Name : Arduino UNO R3 SKU : A000066 Built-in LED Pin : 13 Digital I/O Pins : 14 Analog input pins : 6 PWM pins : 6 UART : Yes I2C : Yes SPI : Yes I/O Voltage : 5V Input voltage (nominal) : 7-12V DC Current per I/O Pin : 20 mA Power Supply Connector : Barrel Plug Main Processor : ATmega328P 16 MHz USB-Serial Processor : ATmega16U2 16 MHz ATmega328P : 2KB SRAM, 32KB FLASH, 1KB EEPROM Weight : 25 g Width : 53.4 mm Length : 68.6 mm Specific data ------------------------------------- Main Processor : ATmega328P 16 MHz PS D:\Formation\Python\WebCrawler>
Retrieving data from different pages
Once you’ve mastered these tools and have a good idea of the data to be retrieved and the structure of the web pages, you can scrape data from several pages. In this last example, we’re retrieving technical data from various Arduino boards. To do this, we create a loop that will execute the preceding code on a list of sites
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
import sys
import time
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
GECKOPATH = "D:\\AranaCorp\\Marketing\\Prospects"
sys.path.append(GECKOPATH)
print("Starting Web Crawling ...")
websites = [
"https://docs.arduino.cc/hardware/uno-rev3/",
"https://docs.arduino.cc/hardware/nano/",
"https://docs.arduino.cc/hardware/mega-2560/",
"https://docs.arduino.cc/hardware/leonardo/",
]
#create browser handler
browser = webdriver.Firefox()#Firefox(firefox_binary=binary)
def acceptcookies():
#class="iubenda-cs-accept-btn iubenda-cs-btn-primary
browser.find_elements(By.CLASS_NAME,"iubenda-cs-accept-btn")[0].click()
def waitForElement(locator, timeout ):
elm = WebDriverWait(browser, timeout).until(expected_conditions.presence_of_element_located(locator))
return elm
cookie_accepted=False
for website in websites:
browser.get(website)
time.sleep(2)
if not cookie_accepted: #accept cookie once
myElem =waitForElement((By.CLASS_NAME , 'iubenda-cs-accept-btn'),30)
print("Page is ready!")
acceptcookies()
cookie_accepted = True
else:
myElem =waitForElement((By.CLASS_NAME , 'tabs__item'),30)
#get board name
name = browser.find_element(By.TAG_NAME,'h1').text
#get tab Tech Specs
btn_text = 'Tech Specs'
spec_btn = WebDriverWait(browser, 20).until(expected_conditions.element_to_be_clickable((By.XPATH, "//*[contains(text(),'{}')]".format(btn_text))))
spec_btn.click()
#browser.execute_script("arguments[0].click();", spec_btn) #use script to click
#get all rows and children
print(name+" "+btn_text)
print("-------------------------------------")
tr_elms = browser.find_elements(By.TAG_NAME,'tr')
for tr in tr_elms:
th_elms = tr.find_elements(By.XPATH, '*')
if len(th_elms)>1:
print(th_elms[0].text, " : ", th_elms[1].text)
#get parent and siblings
print("Specific data")
print("-------------------------------------")
try:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Main Processor')]")
except:
data_row = browser.find_element(By.XPATH, "//*[contains(text(),'Processor')]")
data = data_row.find_element(By.XPATH, "following-sibling::*[1]").text
print(data_row.text, " : ", data)
browser.quit()
Starting Web Crawling ... Page is ready! UNO R3 Tech Specs ------------------------------------- Main Processor : ATmega328P 16 MHz Nano Tech Specs ------------------------------------- Processor : ATmega328 16 MHz Mega 2560 Rev3 Tech Specs ------------------------------------- Main Processor : ATmega2560 16 MHz Leonardo Tech Specs ------------------------------------- Processor : ATmega32U4 16 MHz
Combining Selenium and BeautifulSoup
The two libraries can be combined to bring you all their features
from bs4 import BeautifulSoup from selenium import webdriver browser = webdriver.Firefox() browser.get(website) html = browser.page_source content = BeautifulSoup(html, 'lxml') browser.quit()
Applications
- Automate web-based data collection tasks
- Create your own image bank for neural network training
- Find prospects
- Market research



